Managing Data in the Data Hub
This section of the chapter excerpt deals with acquiring, rationalizing, cleansing, transforming, and loading data into the Data Hub.
By: Alex Berson and Larry Dubov
Service provider takeaway: Managing data in the data hub raises concerns of acquiring, rationalizing, cleaning, transforming, and loading data. This section of the chapter excerpt from the book Mastering Data Management and Customer Integration for a Global Enterprise will focus on the procedures and best practices for consultants managing data in the data hub.
Download the .pdf of the chapter here.
Armed with the knowledge of the role of the enterprise data strategy, we can discuss CDI Data Hub concerns that have to deal with acquiring, rationalizing, cleansing, transforming, and loading data into the Data Hub as well as the concerns of delivering the right data to the right consumer at the right time. In this chapter, we also discuss interesting challenges and approaches of synchronizing data in the Data Hub with applications and systems used to source the data in the first place.
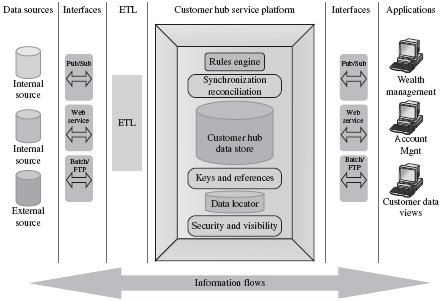
Let's start with the already familiar Data Hub conceptual architecture that we first introduced in Chapter 5. This architecture shows the Data Hub data store and supporting services in the larger context of the data management architecture (see Figure 6-1). From the data strategy point of view, this architecture depicts data sources that feed the loading process, data access and data delivery interfaces, Extract-Transform-Load service layer, the Data Hub platform, and some generic consuming applications.
However, to better position our discussion of the data-related concerns, let's transform our Data Hub conceptual architecture into a view that is specifically designed to emphasize data flows and operations related to managing data in and around the Data Hub.
Data Zone Architecture Approach
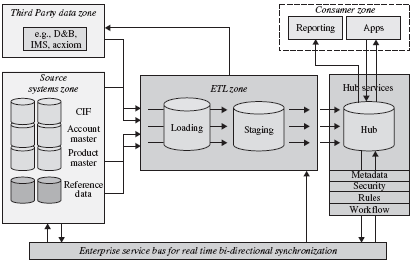
To address data management concerns of the Data Hub environment, we introduce a concept of the data zones and the supporting architectural components and services. The Data Zone architecture illustrated in Figure 6-2 employs sound architecture principles of the separation of concerns and loose coupling.
Turning to nature, consider the difference between simple and complex organisms. Where simple organisms contain several generic cells that perform all life-sustaining functions, a complex organism (e.g., an animal) is "built" from a number of specialized "components" such as heart, lungs, eyes, etc. Each of these components performs its functions in a cooperative fashion together with other components of the body. In other words, when the complexity is low to moderate, having a few generic components simplifies the overall design. But, as the complexity of the system grows, the specialization of components helps address the required functionality in a focused fashion, by organizing groups of concerns into separate specifically designed components.
When we apply these architecture principles to the data architecture view of the Data Hub, we can clearly delineate several functional domains, which we call zones. The Data Zones shown in Figure 6-2 include the following:
- Source Systems zone
- Third-party Data provider zone
- ETL/Acquisition zone
- Hub Services zone
- Information Consumer zone
- Enterprise Services Bus zone
To make it very clear, this zone structure is a logical design construct that should be used as a guide to help solve the complexity of data management issues. The Zone Architecture approach allows architects to consider complex data management issues in the context of the overall enterprise data architecture. As a design guide, it does not mean that a Data Hub implementation has to include every zone and every component. A specific CDI implementation may include a small subset of the data zones and their respective processes and components. Let's review the key concerns addressed by the data zones shown in Figure 6-2.
- The Source Systems zone is the province of existing data sources, and the concerns of managing these sources include good procedural understanding of data structures, content, timeliness, update periodicity, and such operational concerns as platform support, data availability, data access interfaces, access methods to the data sources, batch window processing requirements, etc. In addition to the source data, this zone contains enterprise reference data, such as code tables used by an organization to provide product-name-to-product-code mapping, state code tables, branch numbers, account type reference tables, etc. This zone contains "raw material" that is loaded into the Data Hub and uses information stored in the metadata repository to determine data attributes, formats, source system names, and location pointers.
- The Third-Party zone deals with external data providers and their information. An organization often purchases this information to cleanse and enrich input data prior to loading it into a target environment such as a Data Hub. For example, if the Data Hub is designed to handle customer information, the quality of the customer data loaded into the Data Hub would have a profound impact on the linking and matching processes as well as on the Data Hub's ability to deliver an accurate and complete view of a customer. Errors, use of aliases, and lack of standards in customer name and address fields are most common and are the main cause of poor customer data quality. To rectify this problem an organization may decide to use a third-party data provider that specializes in maintaining an accurate customer name and address database (for example, Acxiom, D&B, etc.). The third-party data provider usually would receive a list of records from an organization, would match them against the provider's database of verified and maintained records, and would send updated records back to the organization for processing. Thus the third-party zone is concerned with the following processes:
- Creating a file extract of customer records to be sent to the provider
- Ensuring that customer records are protected and that only absolutely minimal necessary information is sent to the provider in order to protect confidential data
- Receiving an updated file of cleansed records enriched with accurate and perhaps additional information
- Making the updated file available for the ETL processing
- Making appropriate changes to the content of the metadata repository for use by other data zones
- The ETL/Acquisition zone is the province of data extract, transformation, and loading (ETL) tools and corresponding processes. These tools are designed to extract data from known structures of the source systems based on prepared and validated source-to-target data mapping; transforming input formats of the extracted files into a predefined target data store format (e.g., a Data Hub); and loading the transformed data into the Data Hub using either a standard technique or a proprietary one. The transformations may be quite complex and can perform substitutions, aggregations, and logical and mathematical operations on data attribute values. ETL tools may access an internal or external metadata repository to obtain the information about the transformation rules, integrity constraints, and target Data Hub schema, and therefore can prepare and load the data while preserving various integrity constraints. Many proven, mature solutions can perform ETL operations in an extremely efficient, scalable fashion. They can parallelize all operations to achieve very high performance and throughput on very large data sets. These solutions can be integrated with an enterprise metadata repository and a BI tool repository.
- An effective design approach to the data acquisition/ETL zone is to use a multistage data acquisition environment. To illustrate this point, we consider a familiar analogy of using loading dock for "brick-and-mortar" warehouse facility. Figure 6-2 shows a two-stage conceptual Acquisition/ETL data zone where the first stage, called Loading zone, is acting as a recipient of the data extraction activities. Depending on the complexity and interdependencies involved in data cleansing, enrichment, and transformation, a Loading zone may serve as a facility where all input data streams are normalized into a common, canonical format. The third-party data provider usually receives an appropriate set of data in such a canonical format. The Loading zone is a convenient place where the initial audit of input records can take place.
- The Staging zone, on the other hand, is a holding area for the already cleansed, enriched, and transformed data received from the Loading zone as well as the data processed by and received from a third-party data provider. The Staging zone data structure could be similar to that of the Data Hub. The benefits of having a Staging zone include efficiency in loading data into the Data Hub (most often using a database utility since the transformations are already completed). The Staging zone offers access to a convenient area to perform a record-level audit before completing the load operation. Finally, a Staging zone provides for an easy-to-use, efficient, and convenient Data Hub reload/recovery point that does not depend on the availability of the source systems.
- The Hub Service data zone deals with the data management services that create and maintain the structures and the information content inside the Data Hub. We discussed several of these services in the previous chapter. In this chapter, we discuss Data Hub services that support data synchronization and reconciliation of conflicting data changes. Some Data Hub services use a metadata repository to enforce semantic consistency of the information. Other services include linking, matching, record locator, and attribute locator services.
- The Information Consumer zone is concerned with data-delivery-related issues such as formats, messages, protocols, interfaces, and services that enable effective and easy-to-use access to the required information whether it resides in the Data Hub or in the surrounding systems. The Information Consumer zone is designed to provide data to support business applications including Business Intelligence applications, CRM, and functional applications such as account opening and maintenance, aggregated risk assessment, and others. The Information Consumer zone enables persistent and virtual, just-in-time data integration technologies including Enterprise Information Integration (EII) solutions. Like other data zones, the information consumer zone takes advantage of the metadata repository to determine data definitions, data formats, and data location pointers.
- The Enterprise Service Bus (ESB) zone deals with technologies, protocols, message formats, interfaces, and services that support a message-based communication paradigm between all components and services of the CDI data architecture. The goal of ESB is to support the loosely coupled nature of the Data Hub service-oriented architecture (SOA) by providing a message-based integration mechanism that ensures guaranteed, once and only once, sequence-preserving, transactional message delivery.
Now that we have reviewed the content and purpose of the architecture zones, we can expand these concepts by including several high-level published services that are available to various data architecture components including Data Hub. These services include
- Data acquisition services
- Data normalization and enrichment services
- Data Hub management services
- Data synchronization and reconciliation services
- Data location and delivery services
We discuss some of these services in Chapter 5. The following sections offer a discussion on additional data management services in the context of the Data Zone architecture.
Loading Data in the Data HubData architecture concerns discussed in the beginning of this section have a profound impact on the overall Data Hub architecture and in particular, its data management and data delivery aspects. The Data Zone architecture view shown in Figure 6-2 can help define new effective design patterns, additional services and components that would support any generic data integration platform, and in particular, a Data Hub system for Customer Data Integration.
The level of abstraction of the data zone architecture is sufficiently high to be applicable equally well to all major styles of the Data Hub design including Registry style, Reconciliation Hub style, and ultimately, full Transaction Hub style. However, as we take a closer look at these design styles, we discover that the way the data is loaded and synchronized varies significantly from one style to another.
Indeed, consider the key difference between these styles -- the scope of data for which the Hub is the master, specifically:
- The Registry style of a Data Hub represents a master of unique identifiers of customer "match groups" and all key attributes (often called identity attributes) that allow Data Hub Linking and Matching services to generate these unique persistent identifiers. The Registry-style Data Hub maintains links with data sources for the identity attributes to provide a clear synchronization path between data sources and the Data Hub. The Registry-style Data Hub allows the consuming application to either retrieve or assemble an integrated view of customers or parties at run time.
- The Reconciliation Engine style (sometimes also called Coexistence Hub) supports an evolutionary stage of the Data Hub that enables coexistence between the old and new masters, and by extension, provides for a federated data ownership model that helps address both inter- and intraorganizational challenges of who controls which data. The Data Hub of this style is a system of record for some but not all data attributes. It provides active synchronization between itself and the systems that were used to create the Hub data content or still maintain some of the Hub data attributes inside their data stores. By definition of the "master," the data attributes for which the Data Hub is the master need to be maintained, created, and changed in the Data Hub. These changes have to be propagated to the upstream and downstream systems that use these data attributes. The goal is to enable synchronization of the data content between the Data Hub and other systems on a continuous basis. The complexity of this scenario increases dramatically as some of the data attributes maintained in the Data Hub are not simply copied but rather derived using business-defined transformations on the attributes maintained in other systems.
- The Transaction Hub represents a design style where the Hub maintains all data attributes about the target subject area. In the case of a CDI Data Hub, the subject area is the customer (individuals or businesses). In this case, the Data Hub becomes a "master" of customer information, and as such should be the source of all changes that affect any data attribute about the customer. This design approach demands that the Data Hub is engineered as a complete transactional environment that maintains its data integrity and is the sole source of changes that it propagates to all downstream systems that use this data.
A conceptual Data Hub architecture shown in Figure 6-1 and its Data Zone viewpoint shown in Figure 6-2 should address several common data architecture concerns:
- Batch and real-time input data processing Some or all data content in the Data Hub is acquired from existing internal and external data sources. The data acquisition process affects the Source System zone, the Third-Party Data Provider zone, and the Data Acquisition/ETL zone. It uses several relevant services including data acquisition services, data normalization and enrichment services, and Data Hub management services such as Linking and Matching, Key Generation, Record Locator, and Attribute Locator services (see Chapters 4 and 5 for more details). Moreover, the data acquisition process can support two different modes -- initial data load and delta processing of incremental changes. The former implies a full refresh of the Data Hub data content, and it is usually designed as a batch process. The delta processing mode may support either batch or real-time processing. In the case of batch design, the delta processing, at least for the new inserted records, can leverage the same technology components and services used for the initial data load. The technology suite that enables the initial load and batch delta processing has to support high-performance, scalable ETL functionality that architecturally "resides" in the Acquisition/ETL data zone and usually represents a part of the enterprise data strategy and architecture framework. Real-time delta processing, on the other hand, should take full advantage of service-oriented architecture including the Enterprise Service Bus zone, and in many cases is implemented as a set of transactional services that include Data Hub management services and synchronization services.
- Data quality processes To improve the accuracy of the matching and linking process, many Data Hub environments implement data cleaning, standardization, and enrichment preprocessing in the Third-Party Data Provider and Acquisition/ETL zones before the data is loaded into the Data Hub. These processes use data acquisition and data normalization and enrichment services, and frequently leverage external, industry-accepted reference data sources such as Dun & Bradstreet for business information, or Acxiom for personal information.
Data Synchronization
As data content changes, a sophisticated and efficient synchronization activity between the "master" and the "slaves" has to take place on a periodic or an ongoing basis depending on the business requirements. Where the Data Hub is the master, the synchronization flows have to originate from the Hub toward other systems. Complexity grows if an existing application or a data store acts as a master for certain attributes that are also stored in the Data Hub. In this case, every time one of these data attributes changes in the existing system, this change has to be delivered to the Data Hub for synchronization. One good synchronization design principle is to implement one or many unidirectional synchronization flows as opposed to a more complex bidirectional synchronization. In either approach, the synchronization process may require transactional conflict-resolution mechanisms, compensating transaction design, and other synchronization and reconciliation functionality.
A variety of reasons drive the complexity of data synchronization across multiple distributed systems. In the context of a CDI Data Hub, synchronization becomes difficult to manage when the entire data environment that includes Data Hub and the legacy systems is in a peer-to-peer relationship. This is not a CDI-specific issue; however, if it exists, it may defeat the entire purpose and benefits of building a CDI platform. In this case, there is no clear master role assigned to a Data Hub or other systems for some or all data attributes, and thus changes to some "shared" data attributes may occur simultaneously but on different systems and applications. Synchronizing these changes may involve complex business-rules-driven reconciliation logic. For example, consider a typical non-key attribute such as telephone number. Let's assume that this attribute resides in the legacy Customer Information File (CIF), a customer service center (CRM) system, and also in the Data Hub, where it is used for matching and linking of records. An example of a difficult scenario would be as follows:
- A customer changes his/her phone number and makes a record of this change via an online self-service channel that updates CIF. At the same time, the customer contacts a service center and tells a customer service representative (CSR) about the change. The CSR uses the CRM application to make the change in the customer profile and contact records but mistypes the number. As the result, the CIF and the CRM systems now contain different information, and both systems are sending their changes to each other and to the Data Hub for the required record update.
- If the Data Hub received two changes simultaneously, it will have to decide which information is correct or should take precedence before the changes are applied to the Hub record.
- If the changes arrive one after another over some time interval, the Data Hub needs to decide if the first change should override the second, or vice versa. This is not a simple "first-in first-serve" system since the changes can arrive into the Data Hub after the internal CIF and CRM processing is completed, and their timing does not have to coincide with the time when the change transaction was originally applied.
- Of course, you can extend this scenario by imagining a new application that accesses the Data Hub and can make changes directly to it. Then all systems participating in this change transaction are facing the challenge of receiving two change records and deciding which one to apply if any.
This situation is not just possible but also quite probable, especially when you consider that the Data Hub has to be integrated into an existing large enterprise data and application environment. Of course, should the organization implement a comprehensive data governance strategy and agree to recognize and respect data owners and data stewards, it will be in a position to decide on a single ownership for each data attribute under management. Unfortunately, not every organization is successful in implementing these data management structures. Therefore, we should consider defining conceptual Data Hub components that can perform data synchronization and reconciliation services in accordance with a set of business rules enforced by a business rules engine (BRE).
About the book
Master Data Management and Customer Data Integration for a Global Enterprise explains how to grow revenue, reduce administrative costs, and improve client retention by adopting a customer-focused business framework. Learn to build and use customer hubs and associated technologies, secure and protect confidential corporate and customer information, provide personalized services, and set up an effective data governance team. Purchase the book from McGraw-Hill Osborne Media.
Reprinted with permission from McGraw-Hill from Master Data Management and Customer Data Integration for the Global Enterprise by Alex Berson and Larry Dubov (McGraw-Hill, 2007)







