HA cluster configuration: Requirements and steps
Consider these requirements and settings, such as admission control, prior to a HA cluster configuration and use the HA restart priority and isolation response post-configuration.
Solutions provider takeaway: This chapter excerpt will detail the requirements for HA cluster configuration as well as settings, such as admission control, for you to be aware of. Take a look at what HA restart priority and isolation response can do for your customers' virtual machines.
Configuring HA
Before I detail how to set up and configure the HA feature, let's review the requirements of HA. To implement HA, all of the following requirements should be met:
- All hosts in an HA cluster must have access to the same shared storage locations used by all virtual machines on the cluster. This includes any Fibre Channel, iSCSI, and NFS datastores used by virtual machines.
- All hosts in an HA cluster should have an identical virtual networking configuration. If a new switch is added to one host, the same new switch should be added to all hosts in the cluster.
- All hosts in an HA cluster must resolve the other hosts using DNS names.
About the book
This chapter excerpt on Ensuring High Availability and Business Continuity (download PDF) is taken from the book Mastering VMware vSphere 4. The book offers guidance and insight into implementing VMware vSphere 4. Solutions providers can learn about saving their customers hardware costs during implementation, how to partition a server into several virtual machines and ways to alleviate virtual server sprawl. You can also read through chapters on installing and configuring vCenter Server and vCenter Update Manager, creating and managing virtual networks, ensuring high availability and more.
A Test for HA
An easy and simple test for identifying HA capability for a virtual machine is to perform a VMotion. The requirements of VMotion are actually more stringent than those for performing an HA failover, though some of the requirements are identical. In short, if a virtual machine can successfully perform a VMotion across the hosts in a cluster, then it is safe to assume that HA will be able to power on that virtual machine from any of the hosts. To perform a full test of a virtual machine on a cluster with four nodes, perform a VMotion from node 1 to node 2, node 2 to node 3, node 3 to node 4, and finally, node 4 back to node 1. If it works, then you have passed the test!
First and foremost, to configure HA, you must create a cluster. After you create the cluster, you can enable and configure HA. Figure 11.18 shows a cluster enabled for HA.
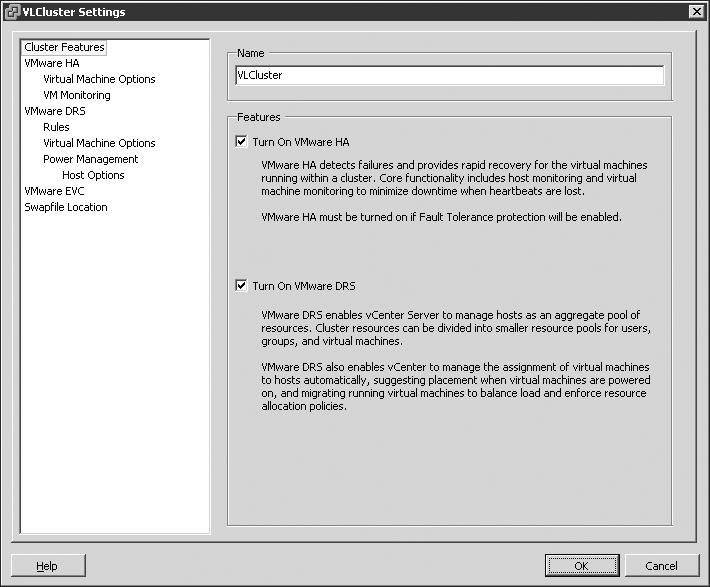
Figure 11.18
A cluster of ESX/ESXi hosts can be configured with HA and DRS. The features are not mutually exclusive and can work together to provide availability and performance optimization.
Configuring an HA cluster revolves around three different settings:
- Host failures allowed
- Admission control
- Virtual machine options
The configuration option for the number of host failures to allow, shown in Figure 11.19, is a critical setting. It directly influences the number of virtual machines that can run in the cluster before the cluster is in jeopardy of being unable to support an unexpected host failure. vSphere now gives up the capability to set a percentage for the failover spare capacity or specify a specific node for failover.
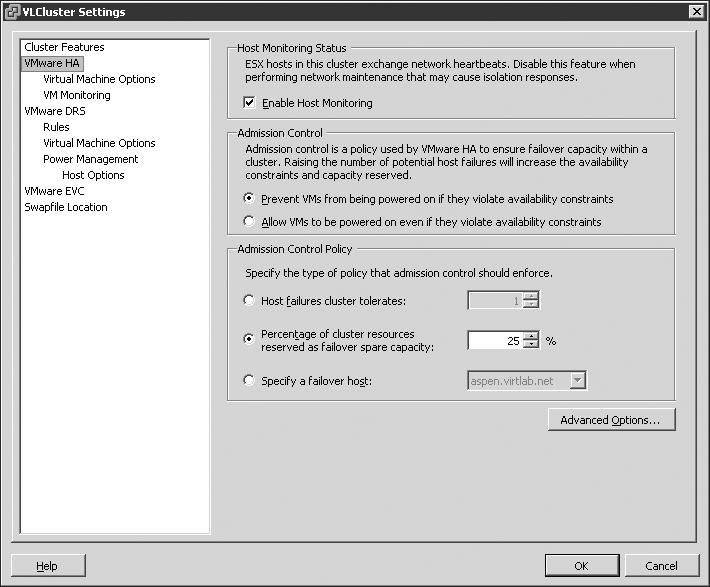
Figure 11.19
The number of host failures allowed dictates the amount of spare capacity that must be retained for use in recovering virtual machines after failure.
HA Configuration Failure
It is not uncommon for a host in a cluster to fail during the configuration of HA. Remember the stress we put on DNS, or name resolution in general, earlier in this chapter? Well, if DNS is not set correctly, you will find that the host cannot be configured for HA. Take, for example, a cluster with three nodes being configured as an HA cluster to support two-node failure. Enabling HA forces a configuration of each node in the cluster. The image here shows an HA cluster where one of the nodes, Silo 104, has thrown an error related to the HA agent and is unable to complete the HA configuration.
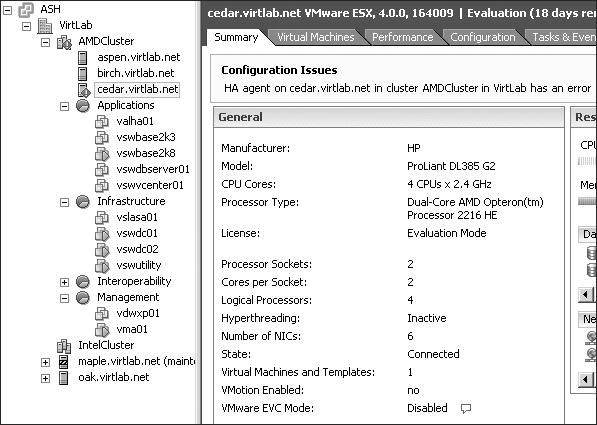
In this example, because the cluster was attempting to allow for two-node failure and there are only two nodes successfully configured, this would be impossible. The cluster in this case is now warning that there are insufficient resources to satisfy the HA failover level. Naturally, with only two nodes, we cannot cover a two-node failure. The following image shows an error on the cluster because of the failure in Silo 104.
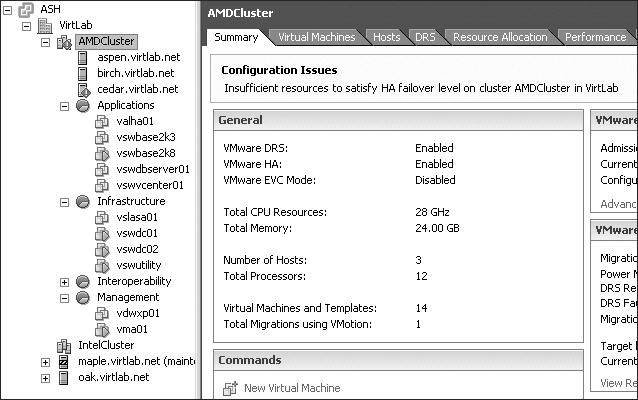
In the Tasks pane of the graphic, you might have noticed that Silo 105 and Silo 106 both completed the HA configuration successfully. This provides evidence that the problem is probably isolated to Silo 104. Reviewing the Tasks & Events tab to get more detail on the error reveals exactly that. The following image shows that the error was caused by an inability to resolve a name. This confirms the suspicion that the error is with DNS.
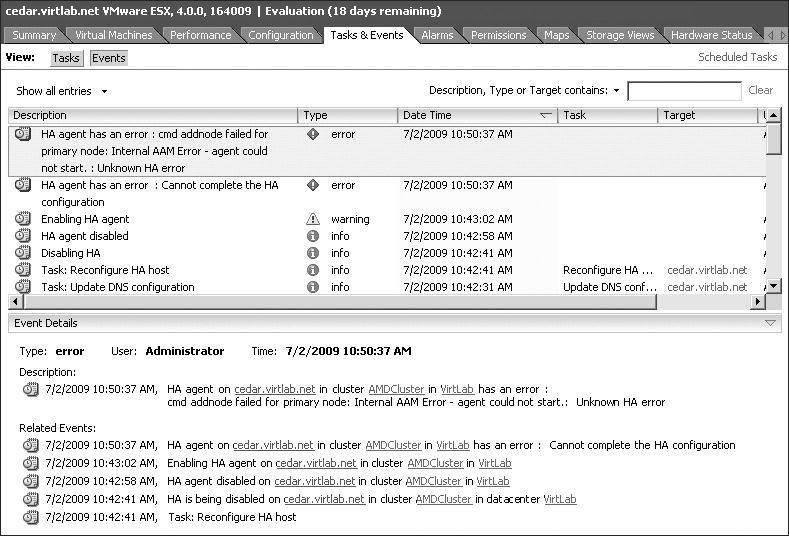
Perform the following steps to review or edit the DNS server for an ESX/ESXi host:
- Use the vSphere Client to connect to a vCenter Server.
- Click the Hosts And Clusters button on the Home page.
- Click the name of the host in the inventory tree on the left.
- Click the Configuration tab in the details pane on the right.
- Select DNS And Routing in the Advanced menu.
- If needed, edit the DNS server, as shown in the following image, to a server that can resolve the other nodes in the HA cluster.

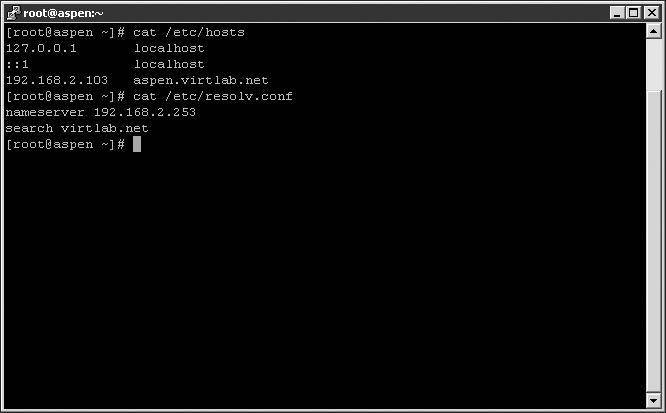
Although they should not be edited on a regular basis, you can also check the /etc/hosts and /etc/resolv.conf files, which should contain static lists of hostnames to IP addresses or the DNS search domain and name servers, respectively. The following image offers a quick look at the information inside the /etc/hosts and /etc/resolv.conf files. These tools can be valuable for troubleshooting name resolution.
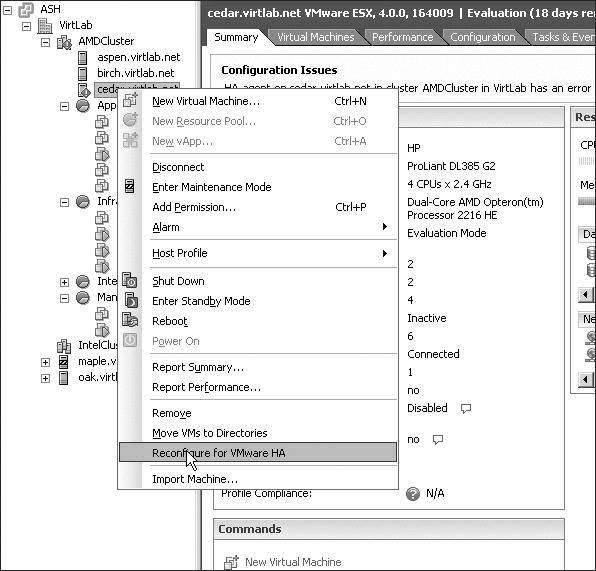
After the DNS server, /etc/hosts, or /etc/resolv.conf has been corrected, the host with the failure can be reconfigured for HA. It's not necessary to remove the HA configuration from the cluster and then reenable it. The following image shows the right-click context menu of Silo 104, where it can be reconfigured for HA now that the name resolution problem has been fixed.
Upon completion of the configuration of the final node, the errors at the host and cluster levels will be removed, the cluster will be configured as desired, and the error regarding the inability to satisfy the failover level will disappear.
To explain the workings of HA and the differences in the configuration settings, let's look at some implementation scenarios. For example, consider five ESX/ESXi hosts named Silo 101 through Silo 105. All five hosts belong to an HA cluster configured to support single-host failure. Each node in the cluster is equally configured with 12GB of RAM. If each node runs eight virtual machines with 1GB of memory allocated to each virtual machine, then 8GB of unused memory across four hosts is needed to support a single-host failure. The 12GB of memory on each host minus 8GB for virtual machines leaves 4GB of memory per host. Figure 11.20 shows our five-node cluster in normal operating mode.
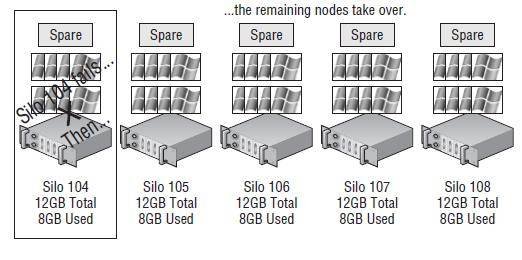
Figure 11.20
A five-node cluster configured to allow single-host failure
Let's assume that Service Console and virtual machine overhead consume 1GB of memory, leaving 3GB of memory per host. If Silo 101 fails, the remaining four hosts will each have 3GB of memory to contribute to running the virtual machines orphaned by the failure. The 8GB of virtual machines will then be powered on across the remaining four hosts that collectively have 12GB of memory to spare. In this case, the configuration supported the failover. Figure 11.21 shows our five-node cluster down to four after the failure of Silo 101. Assume in this same scenario that Silo 101 and Silo 102 both experience failure. That leaves 16GB of virtual machines to cover across only three hosts with 3GB of memory to spare. In this case, the cluster is deficient, and not all of the orphaned virtual machines will be restarted.
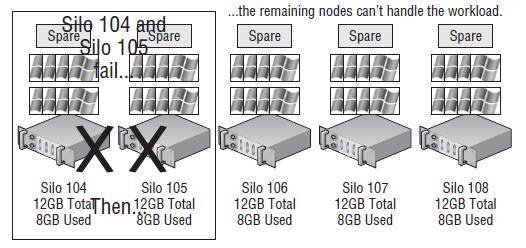
Figure 11.21
A five-node cluster configured to allow single-host failure is deficient in resources to support a second failed node.
Primary Host Limit
In the previous section introducing the HA feature, I mentioned that the AAM caps the number of primary hosts at five. This limitation translates into a maximum of four host failures allowed in a cluster.
The admission control setting goes hand in hand with the Number Of Host Failures Allowed setting. There are two possible settings for admission control:
- Do not power on virtual machines if they violate availability constraints (known as strict admission control).
- Allow virtual machines to be powered on even if they violate availability constraints (known as guaranteed admission control).
In the previous example, virtual machines would not power on when Silo 102 experienced failure because by default an HA cluster is configured to use strict admission control. Figure 11.22 shows an HA cluster configured to use the default setting of strict admission control.
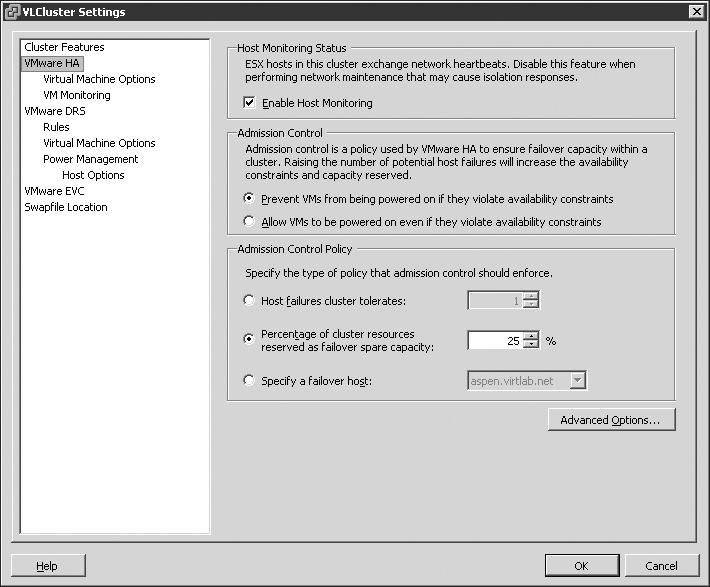
Figure 11.22
Strict admission control for an HA cluster prioritizes resource balance and fairness over resource availability.
With strict admission control, the cluster will reach a point at which it will no longer start virtual machines. Figure 11.23 shows a cluster configured for two-node failover. A virtual machine with more than 3GB of memory reserved is powering on, and the resulting error is posted, stating that insufficient resources are available to satisfy the configured HA level.
If the admission control setting of the cluster is changed from strict admission control to guaranteed admission control, then virtual machines will power on even in the event that the HA failover level is jeopardized.
Figure 11.24 shows a cluster reconfigured to use guaranteed admission control.
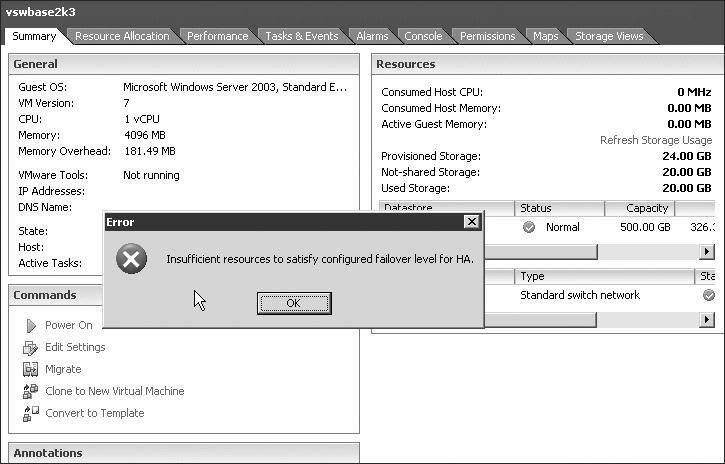
Figure 11.23
Strict admission control imposes a limit at which no more virtual machines can be powered on because the HA level would be jeopardized.
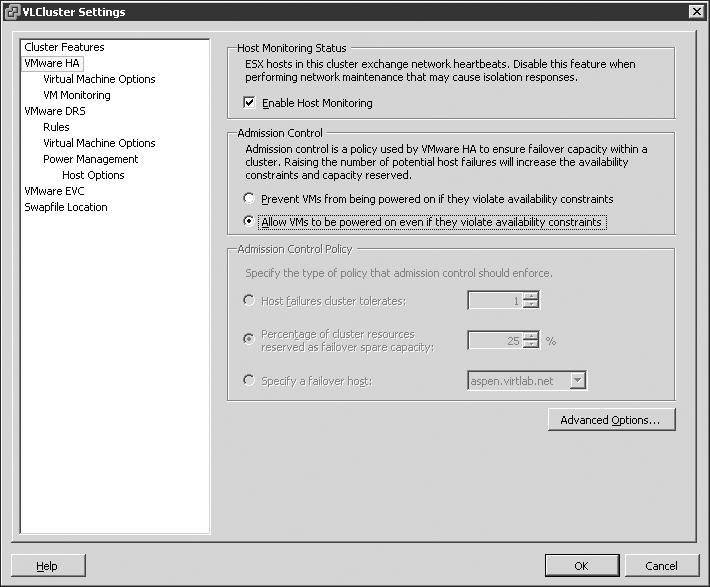
Figure 11.24
Guaranteed admission control reflects the idea that when failure occurs, availability is more important than resource fairness and balance.
With that same cluster now configured with guaranteed admission control, the virtual machine with more than 3GB of memory can now successfully power on.
Overcommitment in an HA Cluster
When the admission control setting is set to allow virtual machines to be powered on even if they violate availability constraints, you could find yourself in a position where there is more physical memory allocated to virtual machines than actually exists.
This situation, called overcommitment, can lead to poor performance on virtual machines that become forced to page information from fast RAM out to the slower disk-based swap file. Yes, your virtual machines will start, but after the host gets maxed out, the whole system and all virtual machines will slow down dramatically. This will increase the amount of time that HA will need to recover the virtual machines. What should have been a 20- to 30-minute recovery could end up being an hour or even more.
HA Restart Priority
Not all virtual machines are equal. There are some that are more important or more critical and that require higher priority when ensuring availability. When an ESX/ESXi host experiences failure and the remaining cluster nodes are tasked with bringing virtual machines back online, they have a finite amount of resources to fill before there are no more resources to allocate to virtual machines that need to be powered on. Rather than leave the important virtual machines to chance, an HA cluster allows for the prioritization of virtual machines. The restart priority options for virtual machines in an HA cluster include Low, Medium, High, and Disabled. For those virtual machines that should be brought up first, the restart priority should be set to High. For those virtual machines that should be brought up if resources are available, the restart priority can be set to Medium and/or Low. For those virtual machines that will not be missed for a period of time and should not be brought online during the period of reduced resource availability, the restart priority should be set to Disabled. Figure 11.25 shows virtual machines with various restart priorities configured to reflect their importance. Figure 11.25 details a configuration where virtual machines such as domain controllers, database servers, and cluster nodes are assigned higher restart priority.
The restart priority is put into place only for the virtual machines running on the ESX/ESXi hosts that experience an unexpected failure. Virtual machines running on hosts that have not failed are not affected by the restart priority. It is possible then that virtual machines configured with a restart priority of High might not be powered on by the HA feature because of limited resources, which are in part because of lower-priority virtual machines that continue to run. For example, as shown in Figure 11.26, Silo 101 hosts five virtual machines with a priority of High and five other virtual machines with priority values of Medium and Low. Meanwhile, Silo 102 and Silo 103 each hold 10 virtual machines, but of the 20 virtual machines between them, only four are considered of high priority. When Silo 101 fails, Silo 102 and Silo 103 will begin powering the virtual machines with a high priority. However, assume there were only enough resources to power on four of the five virtual machines with high priority. That leaves a high-priority virtual machine powered off while all other virtual machines of medium and low priorities continue to run on Silo 102 and Silo 103.
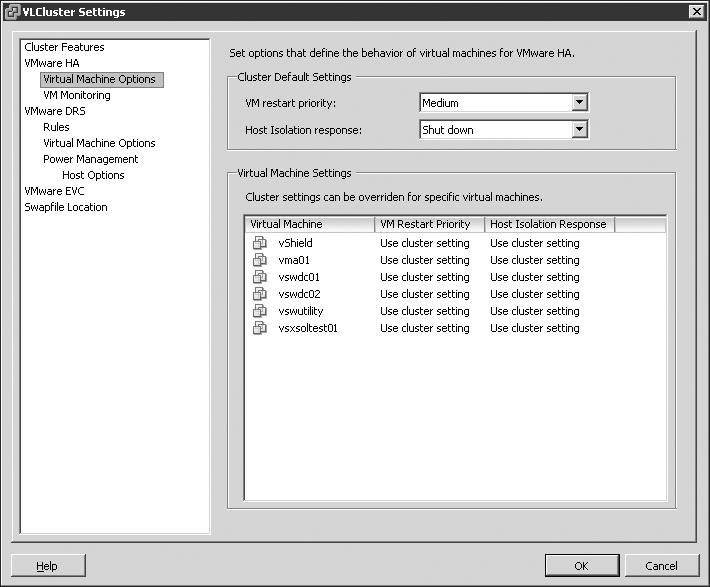
Figure 11.25
Restart priorities help minimize the downtime for more important virtual machines.
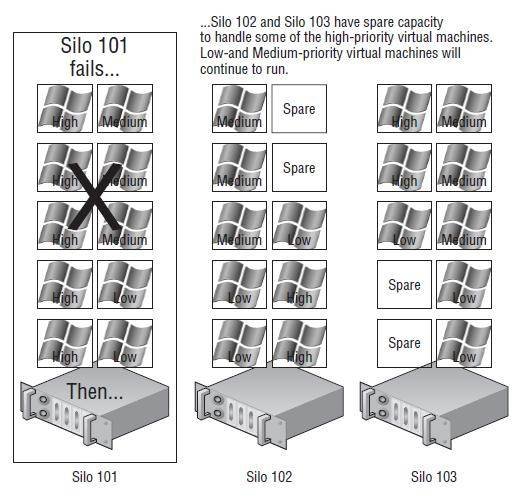
Figure 11.26
High-priority virtual machines from a failed ESX/ESXi host might not be powered on because of a lack of resources—resources consumed by virtual machines with a lower priority that are running on the other hosts in an HA cluster.
At this point in the vSphere product suite, you can still manually remedy this imbalance. Any disaster recovery plan in a virtual environment built on vSphere should include a contingency plan that identifies virtual machines to be powered off to make resources available for those virtual machines with higher priority as a result of the network services they provide. If the budget allows, construct the HA cluster to ensure that there are ample resources to cover the needs of the critical virtual machines, even in times of reduced computing capacity.
HA Isolation Response
Previously, we introduced the AAM and its role in conducting the heartbeat that occurs among all the nodes in the HA cluster. The heartbeat among the nodes in the cluster identifies the presence of each node to the other nodes in the cluster. When a heartbeat is no longer presented from a node in the HA cluster, the other cluster nodes spring into action to power on all the virtual machines that the missing node was running.
But what if the node with the missing heartbeat was not really missing? What if the heartbeat was missing, but the node was still running? And what if the node with the missing heartbeat is still locking the virtual machine files on a SAN LUN, thereby preventing the other nodes from powering on the virtual machines?
Let's look at two particular examples of a situation VMware refers to as a split-brained HA cluster. Let's assume there are three nodes in an HA cluster: Silo 101, Silo 102, and Silo 103. Each node is configured with a single virtual switch for VMotion and with a second virtual switch consisting of a Service Console port and a virtual machines port group, as shown in Figure 11.27.
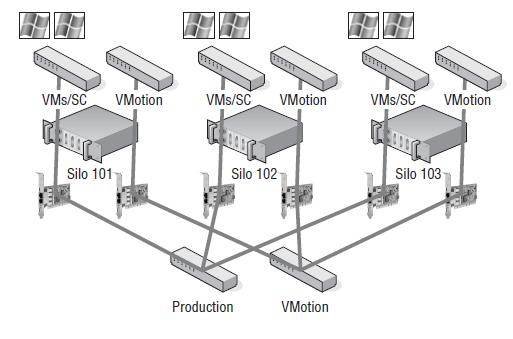
Figure 11.27
ESX/ESXi hosts in an HA cluster using a single virtual switch for Service Console and virtual machine communication
To continue with the example, suppose that an administrator mistakenly unplugs the Silo 101 Service Console network cable. When each of the nodes identifies a missing heartbeat from another node, the discovery process begins. After 15 seconds of missing heartbeats, each node then pings an address called the isolation response address. By default this address is the default gateway IP address configured for the Service Console. If the ping attempt receives a reply, the node considers itself valid and continues as normal. If a host does not receive a response, as Silo 101 wouldn't, it considers itself in isolation mode. At this point, the node will identify the cluster's isolation response configuration, which will guide the host to either power off the existing virtual machines it is hosting or leave them powered on. This isolation response value, shown in Figure 11.28, is set on a per-virtual machine basis. So, what should you do? Power off the existing virtual machine? Or leave it powered on?

Figure 11.28
The isolation response identifies the action to occur when an ESX/ESXi host determines it is offline but powered on.
The answer to this question is highly dependent on the virtual and physical network infrastructures in place. In our example, the Service Console and virtual machines are connected to the same virtual switch bound to a single network adapter. In this case, when the cable for the Service Console was unplugged, communication to the Service Console and every virtual machine on that computer was lost. The solution, then, should be to power off the virtual machines. By doing so, the other nodes in the cluster will identify the releases on the locks and begin to power on the virtual machines that were not otherwise included.
In the next example, we have the same scenario but a different infrastructure, so we don't need to worry about powering off virtual machines in a split-brain situation. Figure 11.29 diagrams a virtual networking architecture in which the Service Console, VMotion, and virtual machines all communicate through individual virtual switches bound to different physical network adapters. In this case, if the network cable connecting the Service Console is removed, the heartbeat will once again be missing; however, the virtual machines will be unaffected because they reside on a different network that is still passing communications between the virtual and physical networks.
Figure 11.30 shows the isolation response setting of Leave Powered On that would accompany an infrastructure built with redundancy at the virtual and physical network levels.
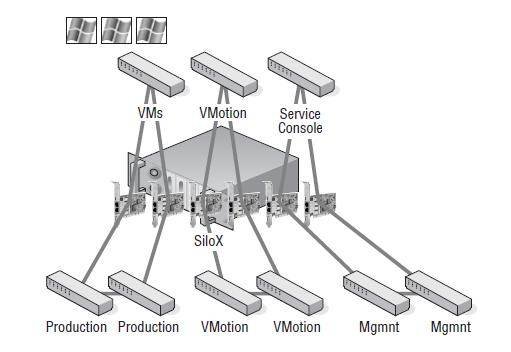
Figure 11.29
Redundancy in the physical infrastructure with isolation of virtual machines from the Service Console in the virtual infrastructure provides greater flexibility for isolation response.
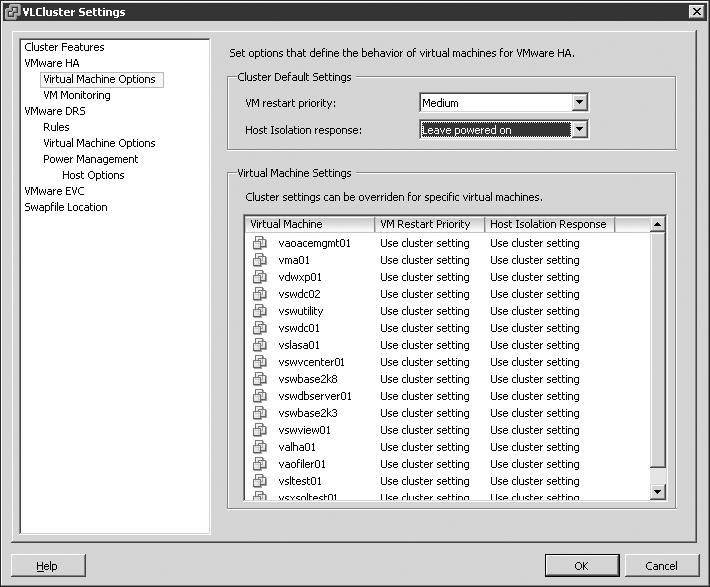
Figure 11.30
The option to leave virtual machines running when a host is isolated should be set only when the virtual and the physical networking infrastructures support high availability.
Configuring the Isolation Response Address
In some highly secure virtual environments, Service Console access is limited to a single, nonrouted management network. In some cases, the security plan calls for the elimination of a default gateway on the Service Console port configuration. The idea is to lock the Service Console onto the local subnet, thus preventing any type of remote network access. The disadvantage, as you might have guessed, is that without a default gateway IP address configured for the Service Console, there is no isolation address to ping as a determination of isolation status.
It is possible, however, to customize the isolation response address for scenarios just like this. The IP address can be any IP address but should be an IP address that is not going to be unavailable or taken from the network at any time.
Perform the following steps to define a custom isolation response address:
- Use the vSphere Client to connect to a vCenter server.
- Open the Hosts And Clusters View, right-click an existing cluster, and select the Edit Settings option.
- Click the VMware HA node.
- Click the Advanced Options button.
- Enter das.isolationaddress in the Option column in the Advanced Options (HA) dialog box.
- Enter the IP address to be used as the isolation response address for ESX/ESXi hosts that miss the AAM heartbeat. The following image shows a sample configuration in which the servers will ping the IP address 172.30.0.2.
-
- Click the OK button twice.
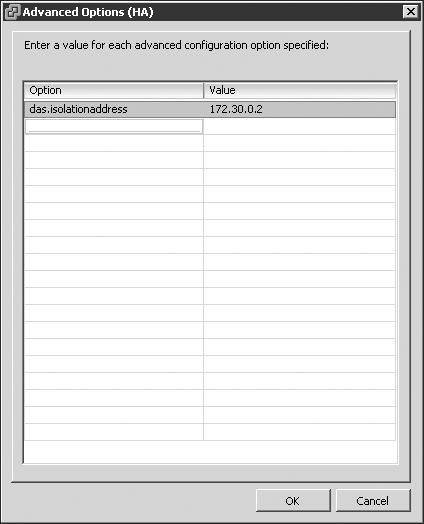
This interface can also be configured with the following options:
- das.isolationaddress1: To specify the first address to try
- das.isolationaddress2: To specify the second address to try
- das.defaultfailoverhost: To identify the preferred host to failover to
- das.failuredetectiontime: To change the amount of time required for failover detection
- das.AllowNetwork: To specify a different port group to use for HA heartbeat
To support a redundant HA architecture, it is best to ensure that the Service Console port is sitting atop a NIC team where each physical NIC bound to the virtual switch is connected to a different physical switch.
Clustering is configured to give you, the administrator of an environment, a form of fault tolerance, and VMware has taken this concept to a whole other level. Although VMware does not call FT clustering, it functions the same in that FT will failover the primary virtual machine to a secondary virtual machine. VMware Fault Tolerance (FT) is based on vLockstep technology and provides zero downtime, zero data loss, and continuous availability for your applications.
That sounds pretty impressive, doesn't it? But how does it work?
![]()
![]() Ensuring High Availability and Business Continuity
Ensuring High Availability and Business Continuity
![]() Using Microsoft Cluster Services for virtual machine clustering
Using Microsoft Cluster Services for virtual machine clustering
![]() VMware HA implementation and ESX/ESXi host addition
VMware HA implementation and ESX/ESXi host addition
![]() HA cluster configuration: Requirements and steps
HA cluster configuration: Requirements and steps
Printed with permission from Wiley Publishing Inc. Copyright 2009. Mastering VMware vSphere 4 by Scott Lowe. For more information about this title and other similar books, please visit Wiley Publishing.
About the author
Scott Lowe has more than 15 years experience in the IT industry and is an expert in virtualization technologies. Lowe is a contributing author for SearchServerVirtualization.com and SearchVMware.com and has received a VMware vExpert Award in 2008 for his work in the VMware and virtualization community. He also has his own virtualization website at blog.scottlowe.org.
Dig Deeper on MSP technology services
-
![]()
Compare VMware HA vs. DRS to prevent host failure
By: Brien Posey
-
![]()
Proxmox VE 6 and later offers container features, better security
By: Robert Sheldon
-
![]()
VSphere High Availability explained: Monitor VMs and applications
By: Allyson Larcom
-
![]()
How to fortify your virtualized Active Directory design
By: Brian Kirsch



