value-added reseller (VAR)

What is a value-added reseller (VAR)?
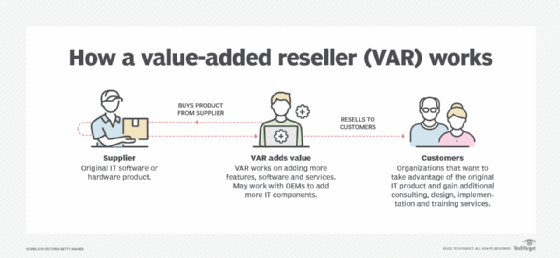
A value-added reseller (VAR) is a company that resells software, hardware and other products and services that provide value beyond the original order fulfillment. VARs package and customize third-party products in an effort to add value and resell them with additional offerings bundled in. This added value can help VARs develop relationships with customers that can potentially lead to repeat business.
Value-added resellers are an important distribution channel for manufacturers while also providing additional value for the customer. That enhanced value can take a number of forms. For example, it could mean providing additional hardware, installation services or troubleshooting. Traditionally, a VAR creates an application for a particular hardware platform and sells the combination as a turnkey service or tool. In many cases, such bundles target the applications of a specific vertical industry.
In addition to IT products, many VARs offer professional services as their key value add. For example, a VAR may provide consulting, design, implementation and training services around the hardware, software and networking components it resells.
VARs that offer services in addition to products are often referred to as solution providers. Such companies typically form channel partnerships with one or more product vendors for assistance in building and marketing. A product vendor, in turn, may seek out relationships with VARs, providing a reseller program as part of a broader channel strategy.
Partnering with vendors
Value-added reseller firms sometimes work directly with an IT vendor, but small VARs in particular may find that some vendors will only sell to them through a two-tier distribution model. In that case, a VAR will source products through a distribution partner.
To work with vendors, reseller partners must become authorized and meet a set of requirements. For example, vendors can require their partners to hit certain revenue targets on an annual basis or to achieve technical and sales certifications through training programs. In exchange for meeting these targets, the vendor will typically provide their VAR partners with incremental financial rewards, support, and other benefits and resources.
Benefits of working with a VAR
Working with a value-added reseller can provide the following benefits:
- Organizations often turn to VARs for assistance with complex IT projects that are too demanding or time-consuming for in-house resources.
- Each VAR has its own portfolio of product offerings and skill sets. Some VARs have expertise working with organizations in specific industries, such as healthcare or financial services, and therefore understand the unique technical and regulatory requirements of their customers.
- A VAR can act as a single point of contact between multiple IT vendors, making it easier for organizations to purchase and manage a variety of technologies.
- VARs are frequently referred to as trusted advisors, and many seek to establish long-term relationships with their customers.
- VARs only mark up a product a small amount; their revenue typically comes from the value-added products and services.
Challenges of working with a VAR
Value-added resellers, however, have the following two main challenges:
- Pricing. VARs cannot control the cost of the product they are selling. In addition, the reselling processes may sometimes be unclear.
- Control. The overall quality of the product is also limited, as the manufacturer of the original product is responsible for quality assurance.
Examples of value-added resellers
Value-added resellers include technology service companies, auto dealerships and even furniture companies.
Technology service companies often offer a range of value-added products or services, such as extended warranties, service contracts, supplemental hardware, software, and installation and setup services.
Likewise, auto dealerships offer value-added products or services such as extended warranties, car rentals, service contracts and custom-made accessory parts.
Even though they are not technology oriented, other companies can also be considered VARs. For example, furniture companies can offer value-added services such as interior decorating or professional design and space planning services.
VAR vs. MSP
A managed service provider (MSP) is a third-party company that remotely manages a customer's IT infrastructure and end-user systems. Small and medium-sized businesses, nonprofits and government agencies hire MSPs to perform a defined set of day-to-day management services.
MSPs typically handle the following functions:
- managing the IT infrastructure;
- offering technical support to staff;
- adding cybersecurity software to IT;
- managing user access accounts;
- handling contract management;
- offering compliance and risk management; and
- providing payroll services.
MSPs and value-added resellers both aid their customers in finding, customizing and maintaining their software or hardware. However, VARs focus on the process of adding new hardware and software while providing additional services, such as recommendations and customization. MSPs also have more recurring revenue services due to lasting contractual relationships with customers.
The VAR business model has evolved over the years. More recently, VARs have started adopting some MSP practices. For example, as product margins decline and competition among software providers intensifies, VARs are looking to managed services as a source of recurring revenue and improved profitability.
VAR vs. OEM
In the IT industry, original equipment manufacturer (OEM) is a term used to describe a variety of businesses that produce component parts for another organization's products. Value-added resellers use OEM products to build a finished product. VARs can purchase the OEM parts and, once purchased, market those parts under the VAR's brand name.
VARs order a specific product from the OEM, which can be anything technical or non-technical in nature. The OEM then builds the specified number of products and sells them to the VAR. The VAR then assembles the components, creating the final product.
Future of VARs
VARs are finding it more difficult to continue in their market due to changes in margins, revenue and competitive positions. These difficulties emanate from different sources, including the widespread adoption of cloud computing services, pricing, movement away from one-stop products, or growth and scaling.
As a result, VARs are transitioning to more of an MSP role. A VAR may become a pure-play MSP or add managed services as a line of business to complement its VAR operation. This helps VARs gain more of a consistent revenue while maintaining margins and competitive position.
One of the advantages of transitioning to a managed services business model is that VARs reduce their dependency on product revenue. But pure-play MSPs are rare, and many VARs continue to rely on a mixture of product and services sales.
A VAR may also seek to become a cloud reseller or consulting firm, although that transition can prove challenging. A security reseller, for example, may be steeped in legacy on-premises technologies and may not have the structure in place to accommodate the pay-as-you-go nature of the cloud model.
As an example, cybersecurity vendors now use the SaaS model to interact with customers. Instead of just providing typical VAR services, VARs in the cybersecurity space are now acting as high-end security assessors, integrators, hybrid cloud consolidators and optimizers, as well as security operations center-as-a-service partners.
Learn how to pick the right IoT partners, and how successful organizations work with VARs.




