Using parallel SQL with Oracle parallel hint to improve database performance
Enhance customers' Oracle database performance by using parallel SQL with an Oracle parallel hint, enabling a SQL statement to be simultaneously processed by multiple threads or processes.
Solution provider's takeaway: Discover how using parallel SQL with Oracle parallel hints will improve your customer's Oracle database performance by using to parallelize SQL statements. Using the information from this chapter excerpt, you can learn how to augment the performance of individual SQLs or the application as a whole.
Parallel SQL enables a SQL statement to be processed by multiple threads or processes simultaneously.
Today's widespread use of dual and quad core processors means that even the humblest of modern computers running an Oracle database will contain more than one CPU. Although desktop and laptop computers might have only a single disk device, database server systems typically have database files spread— striped—across multiple, independent disk devices. Without parallel technology— when a SQL statement is processed in serial—a session can make use of only one of these CPUs or disk devices at a time. Consequently, serial execution of a SQL statement cannot make use of all the processing power of the computer. Parallel execution enables a single session and SQL statement to harness the power of multiple CPU and disk devices.
Parallel processing can improve the performance of suitable SQL statements to a degree that is often not possible by any other method. Parallel processing is available in Oracle Enterprise Edition only.
In this chapter we look at how Oracle can parallelize SQL statements and how you can use this facility to improve the performance of individual SQLs or the application as a whole.
Understanding Parallel SQL
In a serial—nonparallel—execution environment, a single process or thread undertakes the operations required to process your SQL statement, and each action must complete before the succeeding action can commence. The single Oracle process might only leverage the power of a single CPU and read from a single disk at any given instant. Because most modern hardware platforms include more than a single CPU and because Oracle data is often spread across multiple disks, serial SQL execution cannot take advantage of all the available processing power.
For instance, consider the following SQL statement:
SELECT *
FROM sh.customers
ORDER BY cust_first_name, cust_last_name, cust_year_of_birth
If executing without the parallel query option, a single process would be responsible for fetching all the rows in the CUSTOMERS table. The same process would be responsible for sorting the rows to satisfy the ORDER BY clause. Figure 13-1 illustrates the workflow.
We can request that Oracle execute this statement in parallel by using the PARALLEL hint:
SELECT /*+ parallel(c,2) */ *
FROM sh.customers c
ORDER BY cust_first_name, cust_last_name, cust_year_of_birth
If parallel processing is available, the CUSTOMERS table will be scanned by two processes in parallel. A further two processes will be employed to sort the resulting rows. A final process—the session that issued the SQL in the first place—combines the rows and returns the result set. The process that requests and coordinates the parallel processing stream is the Query coordinator. Figure 13-2 illustrates this sequence of events.
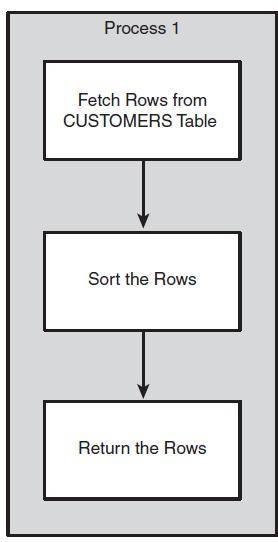
Figure 13-1 Serial execution of a SQL statement.
Oracle supports parallel processing for a wide range of operations, including queries, DDL, and DML:
- Queries that involve table or index range scans
- Bulk insert, update, or delete operations
- Table and index creation
- The collection of object statistics using DBMS_STATS (see Chapter 7, "Optimizing the Optimizer")
- Backup and recovery operations using Recovery Manager (RMAN)
Parallel processes and the degree of parallelism
The Degree of Parallelism (DOP) defines the number of parallel streams of execution that will be created. In the simplest case, this translates to the number of parallel slave processes enlisted to support your SQL's execution. However, the number of parallel processes is more often twice the DOP. This is because each step in a nontrivial execution plan needs to feed data into the subsequent step, so two sets of processes are required to maintain the parallel stream of processing.
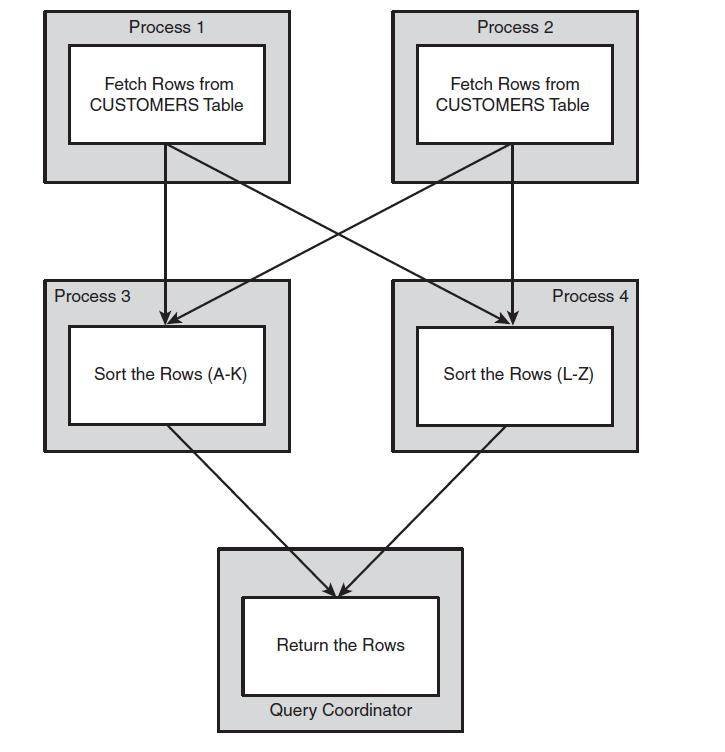
Figure 13-2 Parallel Execution.
For instance, if the statement includes a full table scan, an ORDER BY and a GROUP BY, three sets of parallel processes are required: one to scan, one to sort, and one go group. Because Oracle reuses the first set of parallel processes (those that performed the scan) to perform the third operation (the GROUP BY), only two sets of processes are required. As a result of this approach, the number of parallel slaves allocated should never be more than twice the DOP.
Figure 13-3 shows how parallel slaves are allocated for a DOP of 2.
Parallel slave pool
The Oracle server maintains a pool of parallel slave processes available for parallel operations. The database configuration parameters PARALLEL_MIN_ SERVERS
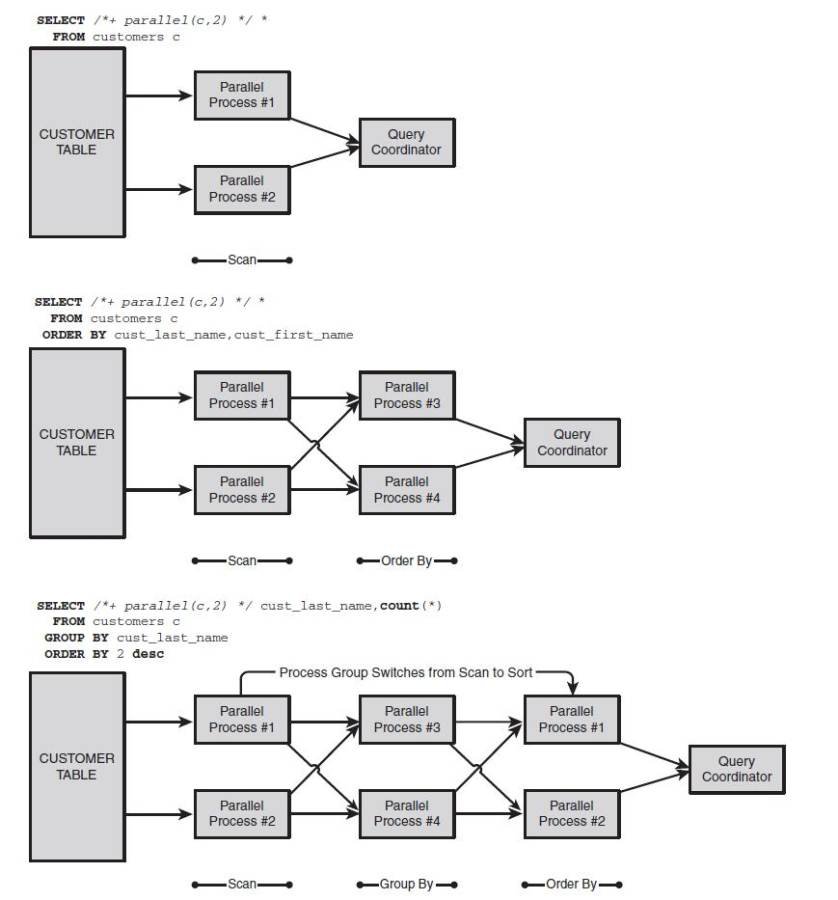
Figure 13-3 Parallel process allocation for a DOP of 2.
and PARALLEL_MAX_SERVERS determine the initial and maximum size of the pool. If insufficient slaves are currently active but the pool has not reached its maximum value, Oracle will create more slaves. After a configurable period of inactivity, slave processes will shut down until the pool is again at its minimum size.
If there are insufficient query processes to satisfy the DOP requested by your statement, one of the following outcomes results:
- If there are some parallel query slaves available, but less than requested by your SQL statement, your statement might run at a reduced DOP.
- If there are no parallel query slaves available, your statement might run serially.
- Under specific circumstances, you might get an error. This will only occur if the database parameter PARALLEL_MIN_PERCENT has been set to a value that is higher than the percentage of required slaves that are available.
- In Oracle 11g Release 2 and forward, your SQL execution might be delayed until sufficient parallel servers are available.
See the "Parallel Configuration Parameters" section later in this chapter for more information on how to configure these outcomes.
Parallel Query IO
We discussed in Chapter 2, "Oracle Architecture and Concepts," and elsewhere, how the Oracle buffer cache helps reduce disk IO by buffering frequently accessed data blocks in shared memory. Oracle has an alternate IO mechanism, direct path IO, which it can use if it determines that it would be faster to bypass the buffer cache and perform the IO directly. For instance, Oracle uses direct IO when reading and writing temporary segments for sorting and intermediate result sets. In Oracle 11g onward, Oracle sometimes uses direct path IO in preference to the normal buffered IO for serial table access as well.
When performing Parallel query operations, Oracle normally uses direct path IO. By using direct path IO, Oracle avoids creating contention for the buffer cache and allows IO to be more optimally distributed between slaves. Furthermore, for parallel operations that perform full table scans the chance of finding matching data in the buffer cache is fairly low, so the buffer cache adds little value.
In Oracle 10g and earlier, parallel query always uses direct path IO, and serial query will always use buffered IO. In 11g, Oracle can use buffered IO for parallel query (from 11g release 2 forward), and serial queries might use direct path IO. However, it remains true that parallel queries are less likely to use buffered IO and might, therefore, have a higher IO cost than serial queries. The higher IO cost will, of course, be shared amongst all the parallel processes so the overall performance might still be superior.
Direct path and buffered IO are discussed in more detail within Chapter 21, "Disk IO Tuning Fundamentals."
Parallel performance gains
The performance improvements that you can expect to obtain from parallel SQL depend on the suitability of your host computer, Oracle configuration, and the SQL statement. If all the conditions for parallel processing are met, you can expect to get substantial performance improvements in proportion to the DOP employed.
On many systems, the limit of effective parallelism will be determined by segment spread, not by hardware configuration. For instance, if you have 32 CPUs and 64 independent disk devices, you might hope for effective parallelism up to at least a DOP of 32 or maybe even 64. However, if the table you are querying is spread over only 6 disks, you are likely to see performance improvements reduce as you increase the DOP beyond 6 or so.
Figure 13-4 illustrates the improvements gained when increasing the DOP for a SQL statement that performs a table scan and GROUP BY of a single table.
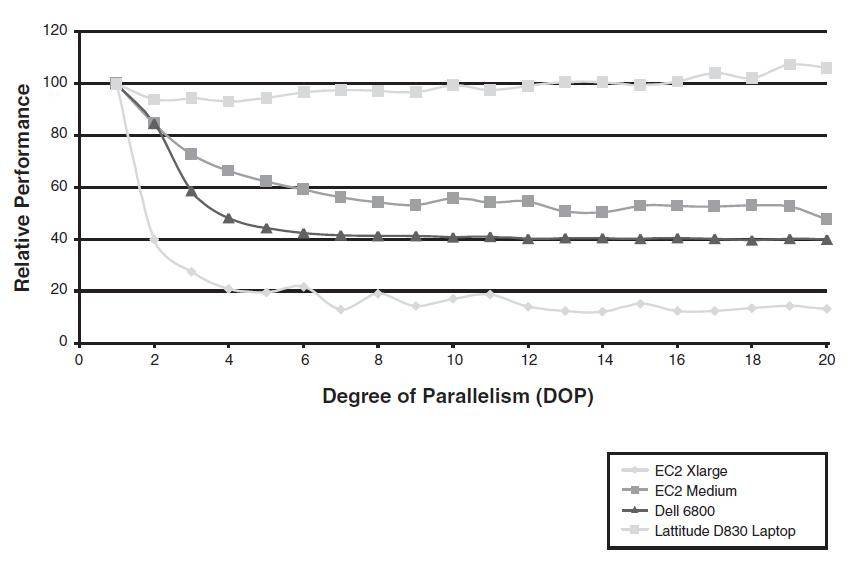
Figure 13-4 Improvement gains for various DOPs on various host configurations.
The host configurations shown are
- An Amazon CPU-intensive Extra Large EC2 image. This is a virtual server running in Amazon's AWS cloud that has the equivalent of 8 _ 2.5-GHz CPUs and has storage on a widely striped SAN.
- An Amazon CPU-intensive Medium EC2 image. This is similar to the extra large image, but has only 2 CPUs.
- A Dell 6800 4 CPU server with disk storage on a widely striped SAN using ASM.
- A Dell latitude D830 laptop (my laptop). It is dual core, but all data files are on a single disk.
In each case, the parallel SQL was the only SQL running.
These examples show that for suitably configured systems, performance gains were greater the more CPUs that were available. However, attempting to use parallel on a host that is unsuitable (as in my laptop) is futile at best and counter-productive at worst.
The performance gains achieved through parallel processing are most dependent on the hardware configuration of the host. To get benefits from parallel processing, the host should possess multiple CPUs and data should be spread across multiple disk devices.
Parallel SQL
- Using parallel SQL to improve Oracle database performance
- Parallel processing: Using parallel SQL effectively
- Parallel execution: Determining SQL suitability, benefits
About the author
Guy Harrison has worked with Oracle databases as a developer, administrator and performance expert for more than two decades. He has also authored MySql Stored Procedure Programming.
About the book
This chapter excerpt on Parallel SQL (download PDF) is taken from the book Oracle Performance Survival Guide: A Systematic Approach to Database Optimization. Get pertinent information on optimizing Oracle performance to maximize customer investment, from application design through SQL tuning.
Printed with permission from Prentice Hall Inc. Oracle Performance Survival Guide: A Systematic Approach to Database Optimization by Guy Harrison. For more information about this title and other similar books, please visit http://prenticehall.com.






